Sync data from PostgreSQL
Sync PostgreSQL tables to Tiger Cloud in real time using the source PostgreSQL connector (livesync)
Livesync vs live migration: The source PostgreSQL connector (livesync) keeps a Tiger Cloud service continuously synchronized with a source PostgreSQL database. It is designed for ongoing replication, not a one-time move. For a one-time database migration with minimal downtime, use live migration instead. The two features use different Docker images and are not interchangeable.
You use the source PostgreSQL connector in Tiger Cloud to synchronize all data or specific tables from a PostgreSQL database to your service in real time. You run the connector continuously, turning PostgreSQL into the primary with your Tiger Cloud service as a logical replica, so you can leverage Tiger Cloud‘s real-time analytics on your replica data without impacting the primary.
The connector uses the established PostgreSQL logical replication protocol, so you get compatibility, familiarity, and a broad knowledge base when adopting it. This is used for data synchronization, not one-off migration.
Use cases include:
- Copy existing data from a PostgreSQL instance to a Tiger Cloud service: up to ~150 GB/hr (recommended minimum 4 CPU/16 GB on both source and target); copy publication tables in parallel (very large tables use a single connection); foreign key validation is disabled during sync so you can sync a table without its referenced tables; and you can track progress via
pg_stat_progress_copyon the source. - Synchronize real-time changes from the source to your service.
- Add and remove tables on demand using the PUBLICATION interface.
- Enable hypertables, columnstore, and continuous aggregates on your logical replica.
Prerequisites
Section titled “Prerequisites”Best practice is to use an Ubuntu EC2 instance hosted in the same region as your Tiger Cloud service to move data. That is, the machine you run the commands on to move your data from your source database to your target Tiger Cloud service.
Before you move your data:
-
Create a target Tiger Cloud service.
Each Tiger Cloud service has a single PostgreSQL instance that supports the most popular extensions. Tiger Cloud services do not support tablespaces, and there is no superuser associated with a service. Best practice is to create a Tiger Cloud service with at least 8 CPUs for a smoother experience. A higher-spec instance can significantly reduce the overall migration window.
-
To ensure that maintenance does not run while migration is in progress, best practice is to adjust the maintenance window.
In addition:
- Find your Tiger Cloud service connection details.
- Install PostgreSQL client tools on your sync machine.
- Make sure the source PostgreSQL instance and the target Tiger Cloud service have the same extensions installed. The connector does not create extensions on the target. If a table uses types from an extension, create that extension on the target service before syncing the table.
Limitations
Section titled “Limitations”- The source PostgreSQL instance must be accessible from the Internet. Services behind a firewall or VPC are not yet supported.
- Indexes, primary keys, unique constraints, and sequences are not migrated. Create the indexes you need on the target service for your query patterns.
- Using TimescaleDB as the source has limited support (no continuous aggregates).
- The source must run PostgreSQL 13 or later.
- Schema changes must be coordinated: make compatible changes on the Tiger Cloud service first, then on the source.
- There is WAL volume growth on the source during large table copy.
- Continuous aggregate invalidation: The connector uses
session_replication_role=replicaduring copy, so table triggers (including those that invalidate continuous aggregates) do not fire. continuous aggregates on the target do not auto-refresh for data inserted during the sync. This applies only to data below the aggregate’s materialization watermark. If the continuous aggregate exists on the source, add it to the connector publication. If it exists only on the target, manually refresh with theforceoption of refresh_continuous_aggregate.
Avoid connection strings that route through poolers like PgBouncer; the connector needs a direct connection to the database.
Set your connection string
Section titled “Set your connection string”Set the connection information for the source database on your sync machine. See Tune your source database on the connector reference for the exact connection string and source configuration.
Tune your source database
Section titled “Tune your source database”Configure the source for logical replication and create a connector user with the right permissions. Choose your source type:
Updating parameters on a PostgreSQL instance will cause an outage. Choose a time that will cause the least issues to tune this database.
- Tune the Write Ahead Log (WAL) on the RDS/Aurora PostgreSQL source database
-
In RDS console, select the RDS instance to migrate.
-
Click
Configuration, scroll down and note theDB instance parameter group, then clickParameter Groups.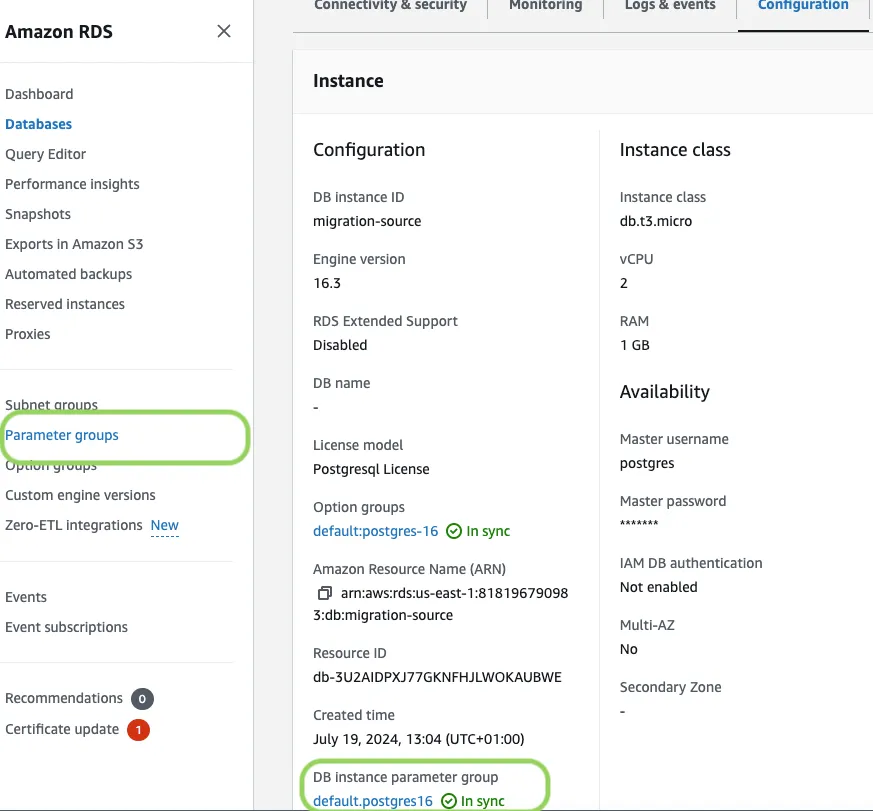
-
Click
Create parameter group, fill in the form with the following values, then clickCreate:Parameter group name, whatever suits your fancy.Description, knock yourself out with this one.Engine type,{C.PG}Parameter group family, the same asDB instance parameter groupin yourConfiguration.
-
In
Parameter groups, select the parameter group you created, then clickEdit. -
Update the following parameters, then click
Save changes:rds.logical_replicationset to1: record the information needed for logical decoding.wal_sender_timeoutset to0: disable the timeout for the sender process.
-
In RDS, navigate back to your databases, select the RDS instance to migrate, and click
Modify. -
Scroll down to
Database options, select your new parameter group, and clickContinue. -
Click
Apply immediatelyor choose a maintenance window, then clickModify DB instance.
Changing parameters will cause an outage. Wait for the database instance to reboot before continuing. After it comes back up, verify that the new settings are in effect on your database.
-
- Create a user for the source PostgreSQL connector and assign permissions
-
Create
<pg connector username>:Terminal window psql $SOURCE -c "CREATE USER <pg connector username> PASSWORD '<password>'"You can use an existing user. However, you must ensure that the user has the following permissions.
-
Grant permissions to create a replication slot:
Terminal window psql $SOURCE -c "GRANT rds_replication TO <pg connector username>" -
Grant permissions to create a publication:
Terminal window psql $SOURCE -c "GRANT CREATE ON DATABASE <database name> TO <pg connector username>" -
Assign the user permissions on the source database:
Terminal window psql $SOURCE <<EOFGRANT USAGE ON SCHEMA "public" TO <pg connector username>;GRANT SELECT ON ALL TABLES IN SCHEMA "public" TO <pg connector username>;ALTER DEFAULT PRIVILEGES IN SCHEMA "public" GRANT SELECT ON TABLES TO <pg connector username>;EOFIf the tables you are syncing are not in the
publicschema, grant the user permissions for each schema you are syncing:Terminal window psql $SOURCE <<EOFGRANT USAGE ON SCHEMA <schema> TO <pg connector username>;GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO <pg connector username>;ALTER DEFAULT PRIVILEGES IN SCHEMA <schema> GRANT SELECT ON TABLES TO <pg connector username>;EOF -
On each table you want to sync, make
<pg connector username>the owner:Terminal window psql $SOURCE -c 'ALTER TABLE <table name> OWNER TO <pg connector username>;'You can skip this step if the replicating user is already the owner of the tables.
-
- Enable replication DELETE and UPDATE operations
Replica identity assists data replication by identifying the rows being modified. Your options are that each table and hypertable in the source database should either have:
- A primary key: data replication defaults to the primary key of the table being replicated. Nothing to do.
- A viable unique index: each table has a unique, non-partial, non-deferrable index that includes only columns marked as
NOT NULL. If a UNIQUE index does not exist, create one to assist the migration. You can delete it after migration. For each table, setREPLICA IDENTITYto the viable unique index:psql -X -d $SOURCE -c ‘ALTER TABLE <table name> REPLICA IDENTITY USING INDEX <_index_name>‘ - No primary key or viable unique index: use brute force. For each table, set
REPLICA IDENTITYtoFULL:
For eachpsql -X -d $SOURCE -c ‘ALTER TABLE <table_name> REPLICA IDENTITY FULL’UPDATEorDELETEstatement, PostgreSQL reads the whole table to find all matching rows. This results in significantly slower replication. If you are expecting a large number ofUPDATEorDELETEoperations on the table, best practice is to not useFULL.
- Tune the Write Ahead Log (WAL) on the PostgreSQL source databasepsql $SOURCE <<EOFALTER SYSTEM SET wal_level='logical';ALTER SYSTEM SET max_wal_senders=10;ALTER SYSTEM SET wal_sender_timeout=0;EOF
This will require a restart of the PostgreSQL source database.
- Create a user for the connector and assign permissions
-
Create
<pg connector username>:psql $SOURCE -c "CREATE USER <pg connector username> PASSWORD '<password>'"You can use an existing user. However, you must ensure that the user has the following permissions.
-
Grant permissions to create a replication slot:
psql $SOURCE -c "ALTER ROLE <pg connector username> REPLICATION" -
Grant permissions to create a publication:
psql $SOURCE -c "GRANT CREATE ON DATABASE <database name> TO <pg connector username>" -
Assign the user permissions on the source database:
psql $SOURCE <<EOFGRANT USAGE ON SCHEMA "public" TO <pg connector username>;GRANT SELECT ON ALL TABLES IN SCHEMA "public" TO <pg connector username>;ALTER DEFAULT PRIVILEGES IN SCHEMA "public" GRANT SELECT ON TABLES TO <pg connector username>;EOFIf the tables you are syncing are not in the
publicschema, grant the user permissions for each schema you are syncing:psql $SOURCE <<EOFGRANT USAGE ON SCHEMA <schema> TO <pg connector username>;GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO <pg connector username>;ALTER DEFAULT PRIVILEGES IN SCHEMA <schema> GRANT SELECT ON TABLES TO <pg connector username>;EOF -
On each table you want to sync, make
<pg connector username>the owner:psql $SOURCE -c 'ALTER TABLE <table name> OWNER TO <pg connector username>;'You can skip this step if the replicating user is already the owner of the tables.
-
- Enable replication DELETE and UPDATE operations
Replica identity assists data replication by identifying the rows being modified. Your options are that each table and hypertable in the source database should either have:
- A primary key: data replication defaults to the primary key of the table being replicated. Nothing to do.
- A viable unique index: each table has a unique, non-partial, non-deferrable index that includes only columns marked as
NOT NULL. If a UNIQUE index does not exist, create one to assist the migration. You can delete it after migration. For each table, setREPLICA IDENTITYto the viable unique index:psql -X -d $SOURCE -c ‘ALTER TABLE <table name> REPLICA IDENTITY USING INDEX <_index_name>‘ - No primary key or viable unique index: use brute force. For each table, set
REPLICA IDENTITYtoFULL:
For eachpsql -X -d $SOURCE -c ‘ALTER TABLE <table_name> REPLICA IDENTITY FULL’UPDATEorDELETEstatement, PostgreSQL reads the whole table to find all matching rows. This results in significantly slower replication. If you are expecting a large number ofUPDATEorDELETEoperations on the table, best practice is to not useFULL.
Synchronize data to your service
Section titled “Synchronize data to your service”Choose your target: sync to Tiger Cloud using Tiger Console, or to a self-hosted TimescaleDB instance using the terminal and the live-sync Docker image.
To sync from your PostgreSQL database to a Tiger Cloud service using Tiger Console:
- Connect to your Tiger Cloud serviceOpen Tiger Console and select the service you want to sync live data into.
- Connect the source database and the target service
- Click
Connectors→PostgreSQL. - Set the connector name (pencil icon).
- Check
Set wal_level to logicalandUpdate your credentials, then clickContinue. - Enter your database credentials or PostgreSQL connection string and click
Connect to database. Tiger Console connects to the source and retrieves schema information.
- Click
- Choose tables and optimize for hypertables
- In the
Select tabledropdown, choose the tables to sync. - Click
Select tables +. Tiger Console checks the schema and, when possible, suggests the time dimension column for a hypertable. - Click
Create Connector. Tiger Console starts the source PostgreSQL connector and shows progress.
- In the
- Monitor synchronization
- Click
Connectorsto seeConnector data flow: Status and amount of data replicated. - For per-table progress:
Connectors→Source connectors→ select your connector.
- Click
- Manage the connector
- Edit:
Connectors→Source connectors→ select the connector. You can rename it, add or remove tables. - Pause: same table → three-dot menu →
Pause. - Delete: three-dot menu →
Delete(pause the connector first).
- Edit:
You’re now syncing the selected tables from your PostgreSQL instance to your Tiger Cloud service in real time.
Sync from a PostgreSQL source using the timescale/live-sync Docker image. The connector runs on a machine that can reach both the source and target databases. The TARGET can be either a Tiger Cloud service or a self-hosted TimescaleDB instance — only the connection string changes.
- Prerequisites for self-hosted target
- A self-hosted TimescaleDB instance (target) and a PostgreSQL source (for example, self-hosted, AWS RDS, or Aurora).
- Docker and PostgreSQL client tools (
psql,pg_dump,pg_restore,vacuumdb) on the sync machine. - The source and target must have the same extensions installed; create any needed extensions on the target before syncing.
- The
<user>in theSOURCEconnection string must have the replication role (to create a replication slot).
- Set your connection strings
On your sync machine, set the source and target connection strings:
Terminal window export SOURCE="postgres://<user>:<password>@<source host>:<source port>/<db_name>"export TARGET="postgres://<user>:<password>@<target host>:<port>/<db_name>"TARGETis the connection string to your Tiger Cloud service or self-hosted TimescaleDB instance. Use your Tiger Cloud service host and port if syncing to Tiger Cloud. Avoid connection strings that route through poolers (for example, PgBouncer); use a direct connection.
Migrate the table schema to your self-hosted target
- Export schema from the source
Terminal window pg_dump $SOURCE \--no-privileges --no-owner --no-publications --no-subscriptions \--no-table-access-method --no-tablespaces --schema-only \--file=schema.sql - Apply the schema on the target
Terminal window psql $TARGET -f schema.sql
Convert time-series tables to hypertables (optional)
On the target, convert tables that hold time-series or event data into hypertables for better performance:
psql -X -d $TARGET -c "SELECT public.create_hypertable('public.<table>', by_range('<time_column>', '<chunk_interval>'::interval));"Example: time column, 1-day chunks:
psql -X -d $TARGET -c "SELECT public.create_hypertable('public.metrics', by_range('time', '1 day'::interval));"- Specify the tables to synchronize
On the source database, create a publication for the tables you want to sync:
CREATE PUBLICATION <publication_name> FOR TABLE <table_name>, <table_name>;- To add tables later:
ALTER PUBLICATION <publication_name> ADD TABLE <table_name>; - To use a partitioned table:
ALTER PUBLICATION <publication_name> SET (publish_via_partition_root = true);
- To add tables later:
- Run the live-sync connector
Run the connector as a long-lived container (for example, daemon). Replace
<publication_name>,<subscription_name>, and optionally<table_map>:Terminal window docker run -d --rm --name livesync timescale/live-sync:v0.11.2 run \--publication <publication_name> \--subscription <subscription_name> \--source $SOURCE \--target $TARGET--publication: name of the publication on the source.--subscription: name for the subscription on the target (identifies this sync).--source/--target: connection strings. Target is your self-hosted TimescaleDB.- Optional
--table-map: for example,'{"source":{"schema":"public","table":"x"},"target":{"schema":"public","table":"y"}}'to map source tables to different target names or schemas. - Optional
--copy-data false: skip initial copy and only replicate changes after the slot is created.
- Monitor and manage
- Logs:
docker logs -f livesync - Progress on target:
psql $TARGET -c "SELECT * FROM _ts_live_sync.subscription_rel" - Replication lag on source: query
pg_replication_slotsforlive_sync_%slots and comparepg_current_wal_flush_lsn()withconfirmed_flush_lsn. - Add/remove tables:
ALTER PUBLICATION <publication_name> ADD TABLE ...orDROP TABLE ...on the source; add tables to the publication as needed. - Stop:
docker stop livesync - Update statistics after initial sync:
vacuumdb --analyze --verbose --dbname=$TARGET
- Logs:
- Clean up when done (--drop)
When you are permanently done syncing (for example, you have fully cut over to Tiger Cloud, or you want to restart the sync from scratch), run the connector with
--dropto remove the replication slot from the source and all subscription state from the target:Terminal window docker run --rm timescale/live-sync:v0.11.2 run \--publication <publication_name> \--subscription <subscription_name> \--source $SOURCE \--target $TARGET \--drop--dropremoves:- The replication slot (
live_sync_<subscription_name>) on the source database. - The subscription and internal tracking tables (
_ts_live_sync.*) on the target database.
WarningRun
--droponly when you intend to permanently stop or fully restart the sync. Dropping the replication slot while the source is still active causes WAL to be retained until the slot is recreated, which can grow disk usage on the source. - The replication slot (
For more detail on the terminal flow (for example, resetting sequences, partitioned tables), see the live migration guide.
For connector capabilities and technical details, see the source PostgreSQL connector reference.